
-
미국의 AI 반도체 시장, 단일 독주에서 다극 경쟁 구도로
- 트렌드
- 미국
- 실리콘밸리무역관 이지현
- 2025-09-26
- 출처 : KOTRA
-
빅테크는 자체 칩을 통해 비용 절감과 효율성 타깃, 스타트업들은 틈새 기술로 차별화 시도
맞춤형 AI 반도체 확산은 칩을 넘어 글로벌 공급망 전반에 새로운 기회 창출
미국에서 AI 활용이 급속 확산되면서 AI 반도체 수요가 폭발적으로 증가하고 있다. IDC 는 2025년 9월 발표한 보고서에서 글로벌 AI 지출이 2029년까지 1조3000억 달러에 이를 것으로 전망했다. 데이터센터와 클라우드 인프라 투자가 AI 반도체 시장 확대를 이끄는 핵심 요인으로 지목했다. AI 반도체는 AI 연산을 처리하는 모든 칩을 포괄하는 개념으로 이 중 AI 가속기는 CPU 보다 빠르고 효율적으로 딥러닝과 추론을 처리하도록 설계된 전용 반도체다. 지금까지는 엔비디아의 GPU 가 AI 가속기 시장을 사실상 독점해왔으나 최근에는 오픈 AI, 메타, 구글, 아마존 등 주요 기업들이 자체적으로 칩 개발에 나서며 판도가 바뀌고 있다.
이러한 흐름은 단순히 미국 내 기술 경쟁을 넘어 TSMC 와 같은 파운드리, SK 하이닉스 ∙ 삼성전자 등 HBM 공급사, 전략반도체, 패키징, 냉각 장비 업체까지 글로벌 공급망 전반에 파급 효과를 미치고 있다. 미국 기업들의 맞춤형 AI 칩 내재화 움직임은 세계 반도체 생태계의 새로운 수요를 촉발하며 한국 기업에도 기회 요인으로 작용할 수 있다.
빅테크는 자체 칩 개발로 엔비디아에 도전장
오픈AI 는 최근 몇 년간 엔비디아 GPU 에 과도하게 의존해온 구조에서 벗어나기 위해 자체 반도체 개발에 나섰다. 2025년 초 로이터 단독 보도에 따르면, 오픈AI 는 TSMC 의 3nm 공정을 활용해 첫 맞춤형 칩 설계를 마무리하고 실제 생산을 위한 최종 준비 단계까지 진행했다. 이 칩은 행렬처럼 배열된 연산 유닛으로 AI 연산 속도를 높이는 ‘시스톨릭 어레이’ 구조와 데이터 전송 속도를 크게 향상 시킨 차세대 고대역폭 메모리(HBM), 그리고 AI 서버 간 빠른 연결을 지원하는 고속 네트워킹 기능이 포함된 것으로 알려졌다. 이는 범용 GPU 보다 대규모 언어모델(LLM) 추론 효율을 크게 높이는 것을 목표로 한다.
이후 2025년 9월 5일, 로이터는 오픈AI 가 브로드컴과 협력해 맞춤형 AI 가속기를 2026년부터 본격 양산할 계획이라고 전했다. 초기 생산분은 외부 판매 없이 오픈 AI 내부 데이터센터에 우선 투입되며 초대형 AI 모델의 추론 작업에 활용될 것으로 전망된다. 업계는 이를 두고 오픈AI 가 장기적으로 자체 반도체 생태계 구축을 위한 첫 걸음을 내디딘 것으로 평가하고 있다.
한편 브로드컴은 고객명을 공식 발표하지 않았으나 최근 2025년 9월에 있었던 실적 발표에서 “새로운 고객으로부터 100억 달러 규모의 AI 인프라 주문을 확보했다”라고 밝혔다. 이를 두고 시장 분석가들은 이 새로운 고객을 오픈AI 로 추정하며 양사 협력의 규모와 파급력이 차차 구체화될 것으로 보고 있다. 다만 첫 시제품 성공 여부, 설계 재검토 가능성, 공급망 제약 등의 변수로 인해 실제 양산 일정과 성능은 유동적일 수 있다는 관측도 나오고 있다.
메타는 엔비디아 GPU 의존도를 줄이고 AI 인프라 비용을 낮추기 위해 자체 반도체 개발 프로젝트인 MTIA(Meta Training and Inference Accelerator, 메타 훈련 및 추론 가속기)를 추진해왔다. 2023년에는 추론용 칩을 페이스북과 인스타그램의 추천 시스템에 적용해 내부 서비스 최적화를 시도하기도 했다.
<메타의 1세대 MTIA 가속기 ‘MTIA v1’이 적용된 샘플 테스트 보드>

[자료: META]
이후 2025년 3월, 로이터는 메타가 첫 번째 훈련 전용 칩 설계를 마무리하고 TSMC 의 첨단 공정을 통해 시제품 생산 단계에 들어갔다고 보도했다. 현재는 소규모 파일럿 테스트를 진행하고 있으며 우선적으로 추천 시스템과 대형 언어모델(LLM) 훈련 성능을 검증하고 있는 것으로 알려졌다. 경영진은 성능이 입증될 경우 2026년부터 데이터센터에 본격적으로 도입할 계획이라고 밝혔다. 이번 훈련용 칩은 기존의 GPU 대비, 전력 효율 개선을 핵심 목표로 설계됐다. AI 훈련 과정에서 방대한 연산 자원과 전력이 소모되기 때문에, 전용 칩이 안정적으로 작동할 경우 메타는 운영비와 에너지 비용을 크게 줄일 수 있을 것으로 기대하고 있다.
재무 측면에서 메타는 2025년 자본지출(CAPEX)을 최대 650억 달러로 제시했으며, 대부분을 AI 인프라 확충에 투입할 계획이다. 같은 해 총 운영비는 1140억~1190억 달러로 전망된다. 업계에서는 이번 움직임을 두고 메타가 엔비디아 GPU 에 전적으로 의존하던 과거에서 벗어나 자립성을 확보하려는 전환점이라 평가하고 있다.
구글은 2025년 4월 열린 Cloud Next ’25 행사에서 7세대 TPU 인 Ironwood 를 공개했다. 구글은 이번 칩이 구글 TPU 가운데 처음으로 추론에 최적화된 것이라고 강조했다. 구글 발표에 따르면 Ironwood 는 이전 세대 TPU 인 Trillium 과 대비해 전력 효율을 두 배 개선했으며 메모리 용량은 6배, 피크 연산 성능은 5배 확장했다. 이 칩들은 최대 9216개를 하나의 클러스터(Pod)로 묶어 운용할 수 있다.
이어 2025년 8월 열린 Hot Chips 2025 학회에서는 Ironwood 의 추가 기술 사양이 소개됐다. 보도에 따르면, Ironwood 는 칩 하나당 192GB의 HBM3e(고대역폭 메모리, 대규모 데이터를 빠르게 처리할 수 있는 차세대 메모리)를 탑재하고 초당 7.3테라바이트의 메모리 대역폭과 FP8 연산 기준 4600 테라플롭스(TFLOPS) 성능을 구현한다. 클러스터로 구성할 경우 약 1.7페타바이트(PB, 1PB는 1000TB) 규모의 공유 메모리를 구현할 수 있다는 점도 공개됐다.
Ironwood 는 현재 구글 데이터센터에서 우선 사용 중이며 구글 자체 AI 모델인 제미나이(Gemini) 서비스에도 적용되고 있다. 구글은 향후 Ironwood 를 구글 클라우드 고객에게 순차적으로 제공할 방침이라고 밝혔다. 업계는 Ironwood 가 엔비디아 GPU 에 대적할 수 있는 대표적 AI 가속기 대안으로 자리잡으며 클라우드 시장의 경쟁 구도를 흔들 수 있는 가능성이 있다고 평가하고 있다.
<기존의 구글 TPU와 최신 모델 Ironwood의 기술 사양 비교>
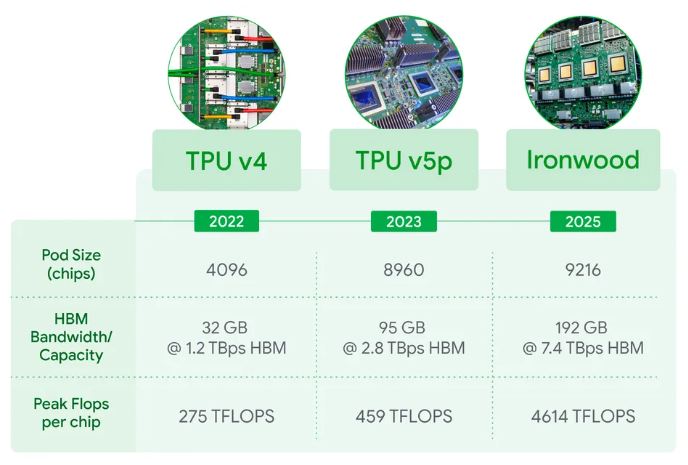
[자료: Google]
아마존은 자사 클라우드 서비스인 AWS 의 경쟁력을 강화하기 위해 일찍부터 자체 설계 AI 칩을 개발해왔다. 2019년에는 Inferentia 를 출시해 추론에 활용했고, 2022년에는 Trainium 을 선보여 대규모 AI 모델 학습에 특화된 전용 칩을 제공했다.
2024년 10월, 월스트리트저널은 아마존이 데이터 · AI 플랫폼 기업 Databricks 와 5년간 협력 계약을 맺었다고 보도했다. 이 협력으로 Databricks 고객은 AWS 에서 제공하는 Trainium과 Inferentia 칩을 활용해 AI 모델을 더 저렴하고 효율적으로 만들고 실행할 수 있다. 업계에서는 이러한 AWS 의 행보를 다른 기업들과 마찬가지로 엔비디아 GPU 에 의존하는 관행에서 벗어나는 동시에 클라우드 환경에 최적화된 자체 칩을 활용해 경쟁력을 강화하려는 것으로 평가하고 있다. 초거대 AI 모델의 학습 · 운영 비용이 빠르게 늘어나는 상황에서, 아마존의 전용 칩과 Databricks 의 AI 플랫폼이 결합하면 기업 고객은 더 낮은 비용으로 다양한 선택지를 확보할 수 있을 것으로 기대된다.
틈새를 파고드는 혁신, 스타트업들의 도전
대기업들이 자체 AI 가속기를 통해 엔비디아 의존도를 낮추고 내부 운영 효율을 높이고 있다면 스타트업들은 특정 기술 분야에 집중해 차별화된 방식으로 시장에 뛰어들고 있다.
대표적인 사례가 에치드(Etched.ai)다. 이 회사는 2022년 하버드대를 Gavin Uberti, Chris Zhu, Robert Wachen이 공동 창업한 스타트업으로, 학생 시절부터 AI 하드웨어 설계와 대형 언어모델(LLM) 학습 구조에 관심을 두고 있었다. 이들은 특히 대형 언어모델의 핵심 구조인 트랜스포머 연산에 최적화된 전용 칩 ASIC ‘Sohu’를 개발하고 있다. 트랜스포머는 단어와 문맥 간의 관계를 계산하는 방식으로, 최신 챗봇과 번역 모델 같은 AI 서비스의 기반이 되는 알고리즘이다. 범용 GPU로 모든 연산을 처리하는 대신, 특정 연산에 최적화된 전용 칩을 통해 효율을 극대화하는 전략을 택한 것이다.
에치드는 2023년 3월 초기 투자에서 540만 달러를 유치한 데 이어, 2024년 6월에는 시리즈 A 라운드에서 1억2000만 달러 규모의 대규모 투자를 확보했다. 이 라운드는 Primary Venture Partners와 Positive Sum Ventures 가 주도했으며 페이팔 공동 창업자인 Peter Thiel 과 Replit CEO 인 Amjad Masad 같은 유명 투자자도 참여해 업계의 주목을 끌었다. 현재 이 회사는 TSMC 와 협력해 칩 생산을 준비 중이다.
<에치드가 개발한 ASIC ‘Sohu’의 모습>

[자료: Etched.ai]
세레브라스 시스템즈(Cerebras Systems)는 2016년 실리콘밸리에 설립된 AI 반도체 스타트업으로 기존 칩 설계의 한계를 정면으로 돌파한 기업으로 평가받고 있다. 이 회사가 개발한 ‘웨이퍼 스케일 엔진(WSE, Wafer Scale Engine)’은 이름 그대로 실리콘 웨이퍼 전체를 하나의 칩으로 활용하는 구조다. 일반적으로 반도체 웨이퍼는 잘게 잘라 여러 개의 칩으로 생산하지만 세레브라스 시스템즈는 웨이퍼를 통째로 사용해 칩 크기 자체를 획기적으로 확대한 것이다.
<세레브라스 시스템즈가 개발한 WSE의 모습>

[자료: Cerebras Systems]
이 접근법을 통해 세레브라스 시스템즈는 수십만 개의 연산 코어와 수십 기가바이트(GB) 수준의 초고속 온칩 메모리를 단일 칩 안에 통합하는 데 성공했다. 덕분에 초대형 언어모델(LLM) 학습처럼 방대한 연산을 요구하는 작업에서 높은 효율성을 발휘한다. 이는 업계에서 흔히 “더 큰 칩이 곧 더 큰 경쟁력”이라는 발상을 실제 제품으로 구현한 사례로 불린다. 현재 이 제품은 메타의 Llama API 서비스 학습 과정에도 활용되고 있다.
또 다른 주목할 기업은 인차지 AI(EnCharge AI)로, 2022년 프린스턴 대학교 연구실에서 분사한 반도체 스타트업이다. 이 기업은 아날로그 인메모리 컴퓨팅(analog in-memory computing) 기술을 기반으로 AI 연산 효율을 높이는 칩을 개발하고 있다. 인차지 AI가 공개한 첫 제품은 ‘EN100’라는 명칭의 AI 가속기 칩으로, 노트북, 워크스테이션, 엣지 디바이스에 적용할 수 있도록 설계됐다. 인차지 AI는 2025년 2월 Tiger Global 등이 주도한 시리즈 B 펀딩 라운드에서 1억 달러 이상을 조달했으며, 이로써 회사의 누적 자금 조달액이 약 1억4400만 달러 수준에 도달했다.
<인차지 AI가 선보인 AI 가속기 칩 ‘EN100’>

[자료: EnCharge AI]
이처럼 스타트업들은 대기업이 아직 집중하지 않은 틈새를 파고들며 특정 연산 구조(에치드), 초대형 연산(세레브라스 시스템즈), 초저전력 환경(인차지 AI) 등 각자의 강점을 기반으로 차별화를 시도하고 있다. 이는 AI 반도체 시장이 단순히 ‘GPU vs. 대체재’ 구도가 아니라, 다양한 수요와 환경에 맞춘 다층적 경쟁 구도로 진화하고 있음을 보여준다.
맞춤형 칩, AI 생태계를 흔들다
최근의 맞춤형 AI 반도체 개발은 개별 기업의 단순한 기술 투자 차원을 넘어, AI 반도체 시장의 판도를 바꾸는 움직임으로 평가되고 있다. 무엇보다 업계에서는 이른바 ‘탈(脫)엔비디아’ 흐름이 두드러지고 있다. 엔비디아의 GPU 는 여전히 업계 표준이지만, 앞서 살펴본 바와 같이 오픈 AI, 메타, 구글, 아마존 같은 빅테크와 여러 스타트업이 자체 칩을 내놓으며 특정 기업에 지나치게 의존하는 위험을 줄이고, 동시에 각사의 서비스 특성에 맞춘 최적화된 연산 성능을 확보하려는 전략이다. 또한 대규모 언어모델 학습과 추론 과정에서 비용과 전력 부담이 늘어나면서, 기업들은 전용 ASIC 이나 XPU 를 통해 효율성을 확보해야 한다는 압박을 받고 있다.
이러한 변화는 미국 내 경쟁을 넘어 글로벌 공급망 전반으로 파급력을 미치고 있다. 빅테크 기업들은 대규모 데이터센터 운영 효율을 높이기 위해 자체 칩을 설계 ∙ 내재화하고, 스타트업들은 특정 연산 구조나 초저전력 분야에 특화해 틈새시장을 공략하고 있다. 하지만 이 모든 과정은 첨단 파운드리, HBM 메모리, 패키징 기술, 전력 반도체, 네트워킹, 냉각 장비 없이는 불가능하다. 따라서 맞춤형 AI 반도체 경쟁은 칩 자체의 성능 경쟁을 넘어, 글로벌 소재∙부품∙장비 산업 전반에 새로운 수요와 기회를 만들어내고 있는 중이다.
AI 반도체 전쟁, 한국 기업의 기회는 어디에?
미국 내 맞춤형 AI 반도체 경쟁은 단기간 유행으로 끝날 사안이 아니다. 업계 전문가들은 이를 두고 “앞으로 10년간 AI 산업 구조를 좌우할 전략적 흐름”이라고 평가하고 있다. 이 과정에서 한국 기업에도 적지 않은 기회가 열릴 것으로 기대된다.
무엇보다 공급망 참여의 여지가 크다. AI 가속기는 GPU 만으로 돌아가지 않는다. HBM(고대역폭 메모리), 전력 반도체, 첨단 패키징, 냉각 장치까지 다양한 부품과 소재가 필요하다. 한 HBM 제조사 관계자는 KOTRA 실리콘밸리 무역관 인터뷰에서 “HBM은 이미 한국이 세계 시장을 주도하고 있고, 전력 반도체도 성장세가 뚜렷하다. 글로벌 기업들의 맞춤형 칩 프로젝트에 자연스럽게 연결될 수 있는 분야”라며, “AI 데이터센터에서는 단순한 메모리칩만이 아니라 모듈 ∙ 패키징 기술까지 요구된다. 한국 기업이 강점을 가진 분야라 글로벌 맞춤형 칩 프로젝트와 연결될 가능성이 크다”라고 덧붙였다.
또한 협력과 투자 전략도 주목된다. 빅테크뿐 아니라 앞서 소개한 에치드, 세레브라스와 같은 신생기업들도 글로벌 파트너를 찾고 있다. 한국 기업들은 단순 납품을 넘어 공동 연구개발(R&D), 전략적 투자, 기술 제휴를 통해 공급망에서 입지를 강화할 수 있다.
엣지와 저전력 시장 역시 기회 요인이다. 인차지 AI 처럼 스마트폰 · 노트북 · IoT 기기를 겨냥한 초저전력 AI 칩 수요가 늘고 있는데, 이는 한국 기업들이 이미 경쟁력을 확보한 모바일 반도체, IoT 모듈, 전력 효율화 기술과 자연스럽게 연결된다.
마지막으로 표준화 경쟁도 간과할 수 없다. AI 반도체가 다양해질수록, 칩과 시스템 간의 호환성을 보장하는 오픈소스 표준의 중요성이 커진다. 한국 기업들이 글로벌 커뮤니티 참여를 통해 표준 선점 효과를 확보한다면, 장기적으로 시장 진입 장벽을 낮추고 협력 기회를 넓힐 수 있을 것이다.
자료: IDC, MIT Tech Review, IEEE Spectrum, Reuters, Wall Street Journal, OpenAI, Meta, Google, AWS, Broadcom, Hot Chips, CNBC, TechCrunch, Crunchbase, Linux Foundation, Open Compute Project, KOTRA 실리콘밸리무역관 자료 종합
<저작권자 : ⓒ KOTRA & KOTRA 해외시장뉴스>

KOTRA의 저작물인 (미국의 AI 반도체 시장, 단일 독주에서 다극 경쟁 구도로)의 경우 ‘공공누리 제4 유형: 출처표시+상업적 이용금지+변경금지’ 조건에 따라 이용할 수 있습니다. 다만, 사진, 이미지의 경우 제3자에게 저작권이 있으므로 사용할 수 없습니다.
-
1
작게·가볍게·친환경적으로…인도네시아 포장산업의 3대 키워드
인도네시아 2025-09-26
-
2
스마트폰 대체할까, 메타가 이끄는 미국 스마트 글라스 시장
미국 2025-09-26
-
3
선박 해체 시장의 중요성 대두, 일본의 대응 현황은?
일본 2025-09-26
-
4
중국 선전에서 열린 세계 최대 광전자 전시회 ‘CIOE 2025’ 참관기
중국 2025-09-25
-
5
뉴트라슈티컬 시장의 성장…‘비타푸드 아시아 2025’에서 본 태국 건강기능식품 트렌드
태국 2025-09-26
-
6
첨단 기술 도입에 '미소 디자인' 열풍…성장하는 베트남 치과 시장
베트남 2025-09-26
-
1
2025년 미국 화장품 산업정보
미국 2025-07-01
-
2
2025년 미국 조선업 정보
미국 2025-05-08
-
3
2024년 미국 반도체 제조 산업 정보
미국 2024-12-18
-
4
2024년 미국 의류 산업 정보
미국 2024-11-08
-
5
2024년 미국 가전산업 정보
미국 2024-10-14
-
6
2024년 미국 리튬 배터리 산업 정보
미국 2024-09-04